

AIでイラストや画像を作るには?
難しい事はわからないので、簡単にできる方法は?
高性能のパソコンなどは持っていないけど大丈夫?
今回は、Stable Diffusionを使って簡単に画像を作る方法を紹介します。
この記事を読めば、すぐに自分で画像を作ることができるようになります。
Stable Diffusionとは
ミュンヘン大学のグループが開発した、入力したテキストから画像を作り出す画像生成モデルです。
コードは一般に公開されているオープンソースで、誰でも無料で使うことができます。
例えば「a rabbit in the forest」と入力すると、こういった画像を生成してくれます。

他にも、このような画像を作ることもできます。

Stable Diffusionを使う3つの方法
- Webサービスで使用する
- クラウド環境(Google Colabなど)で使用する
- ローカル環境(自分のPC)で使用する
Stable Diffusionを使うには、以上の3つがありますが、それぞれのメリットとデメリットは以下の通りです。
| メリット | デメリット | |
|---|---|---|
| Webサービスで使用する | 簡単に、すぐ始めることが可能。低スペックのPCで大丈夫 | 自由度が低い(枚数制限や課金要素、R18禁止など) |
| クラウド環境で使用する | 自由に制限なしで使うことが可能。低スペックのPCで大丈夫 | クラウドの利用料金が必要。利用時間に制限あり。始めるまでが少々面倒 |
| ローカル環境で使用する | 自由に制限なしで使うことが可能 | 高性能のPCが必要。始めるまでが面倒 |
Webサービスで使用する
とりあえず画像生成をやってみたいという方には、Webサービスがお勧めです。
Stable Diffusionが使える有名なサイトはこの3つです。
| 特 徴 | |
|---|---|
| Hugging Face | 画面がシンプルで使いやすい。ログイン不要 |
| Dream Studio | 画像生成が高速。各種設定が可能。ログイン必要 |
| Mage.space | 使用回数に制限なし。ログイン不要 |
では、3つのなかでも一番使いやすい「Hugging Face」での使用法について説明していきます。
「Hugging Face」の「Stable Diffusion 2 Demo」の画面に進みます。
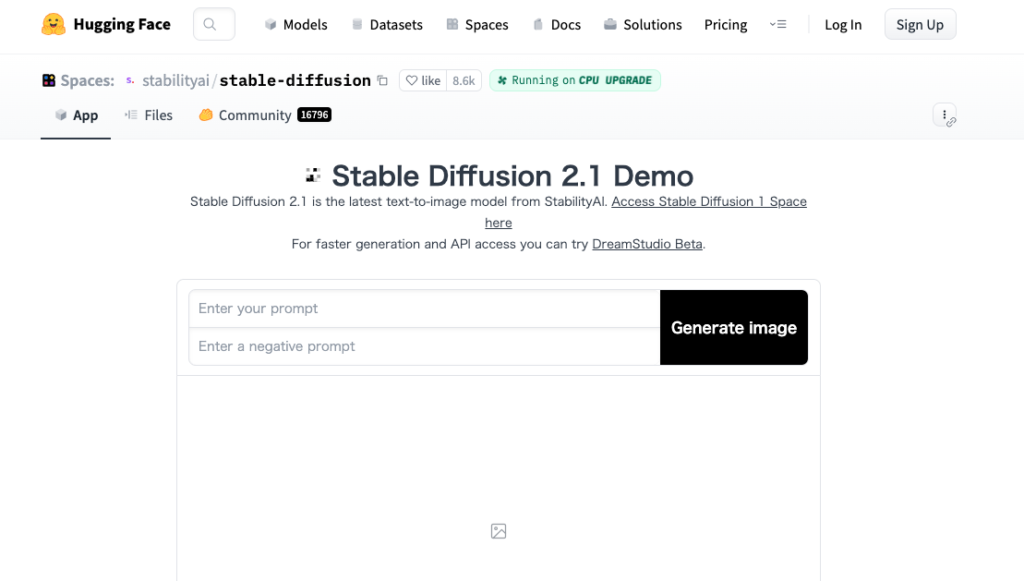
「Enter your prompt」に生成したい画像の説明文を入力します。
今回は「best quality, a rabbit in the wood」と入力してみます。
「Enter a negative prompt」には、生成したい画像に含まれてほしくない要素を入力します。
今回は「low quality」と入力してみます。

うさぎの画像を生成することができました。
クラウド環境(Google Colab)で使用する
現在、Google Colabでは無料のユーザーに対し、Stable Diffusionの使用に制限がかかるようになっています。
よって、Google ColabでStable Diffusionを使用するためには、Colab Pro(月額1,179円)への加入が必要となります。
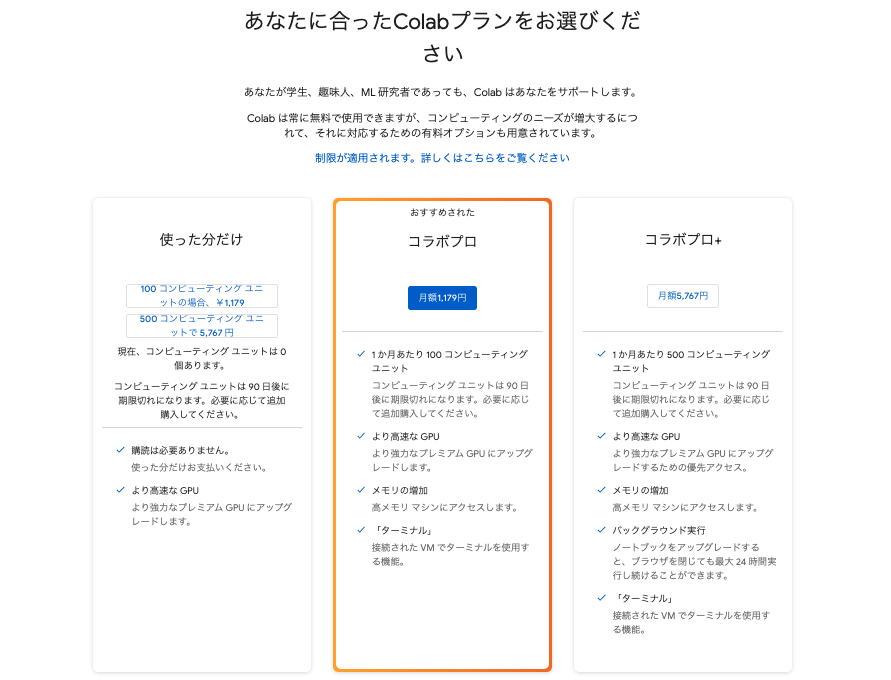
Google Colabにログイン
まず、Google Colabにログインしましょう。
Google Colab用のノートブックをコピー
Automatic1111 WebUI 公式ページにアクセスして、Google Colab用の「maintained by TheLastBen」を開きます。
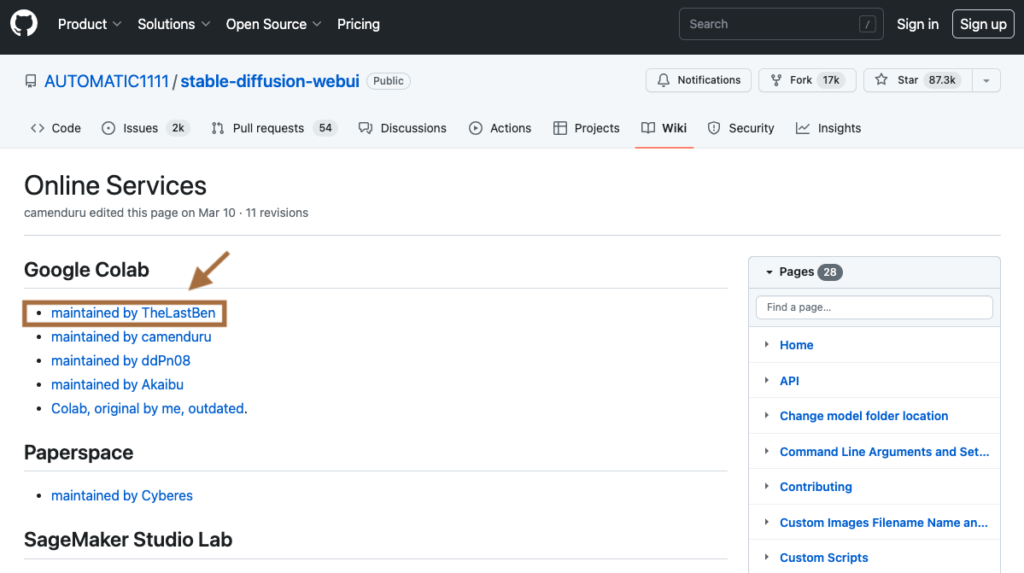
ノートブックを開くと次のような画面が出てきます。
「Copy to Drive」を選択し、自分のGoogle Driveにコピーします。
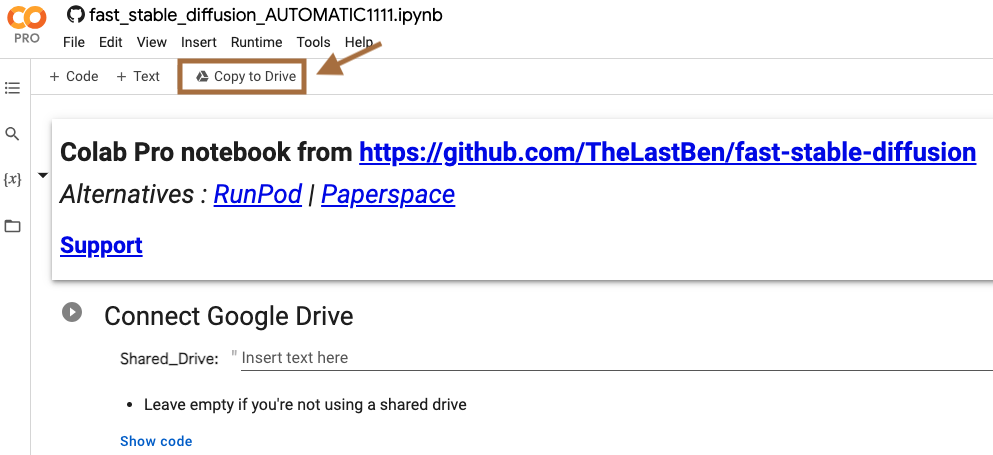
別タブで「Copy of fast_stable_diffusion_AUTOMATIC1111.ipynb」という名前のノートブックが開きます。
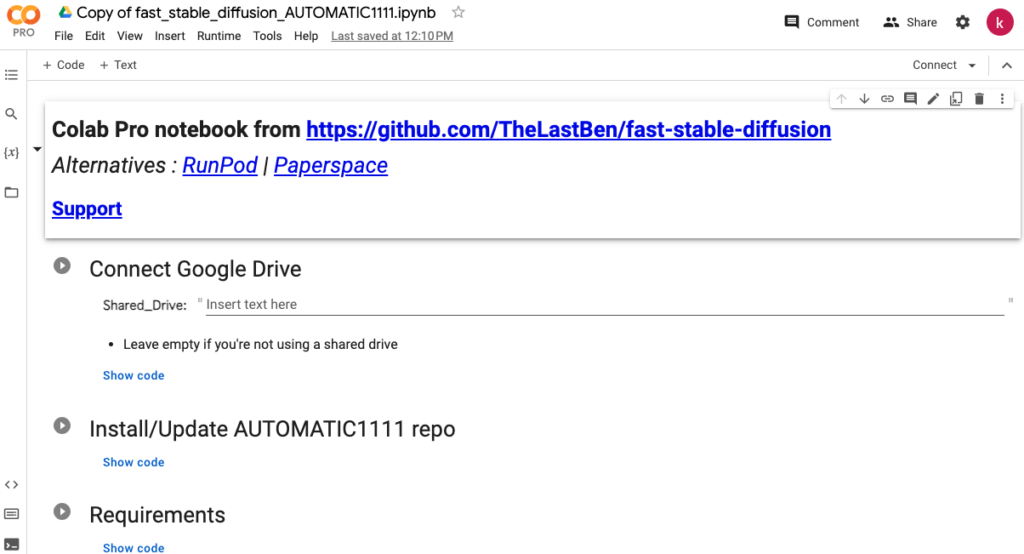
オリジナルのファイルのタブは閉じておいてください。
Stable Diffusionで使うモデルを入手
モデルとは画像のスタイルを決めるファイルです。
「CIVITAI」や「Hugging face」からダウンロードできます。
今回は、「CIVITAI」から二次元イラストが生成できる人気のモデル、「meinamix_meinaV10.safetensors」をダウンロードして使用します。
画面の上の方にある検索窓にモデル名を入れます。
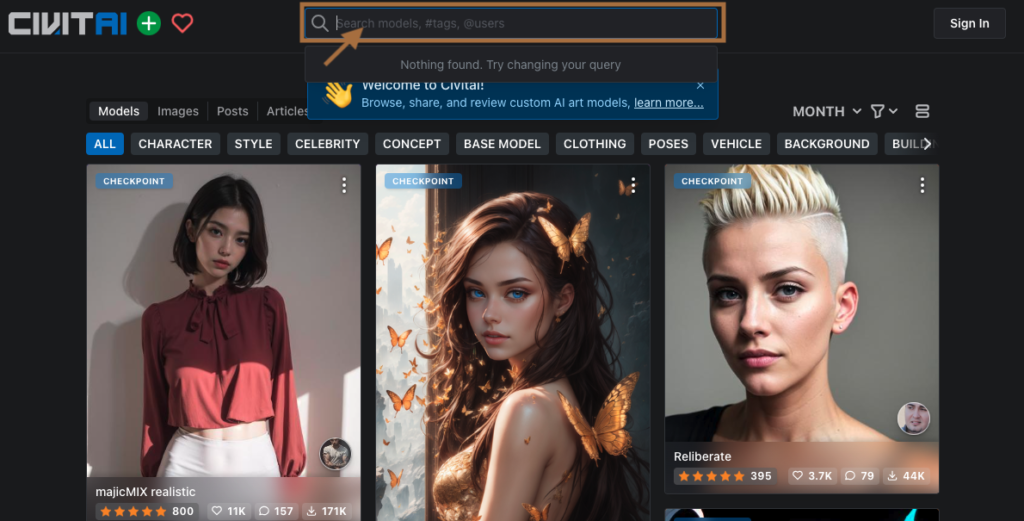
検索して出てきたモデルの画面に移動し、右側の「downlaod」をクリックしてダウンロードします。
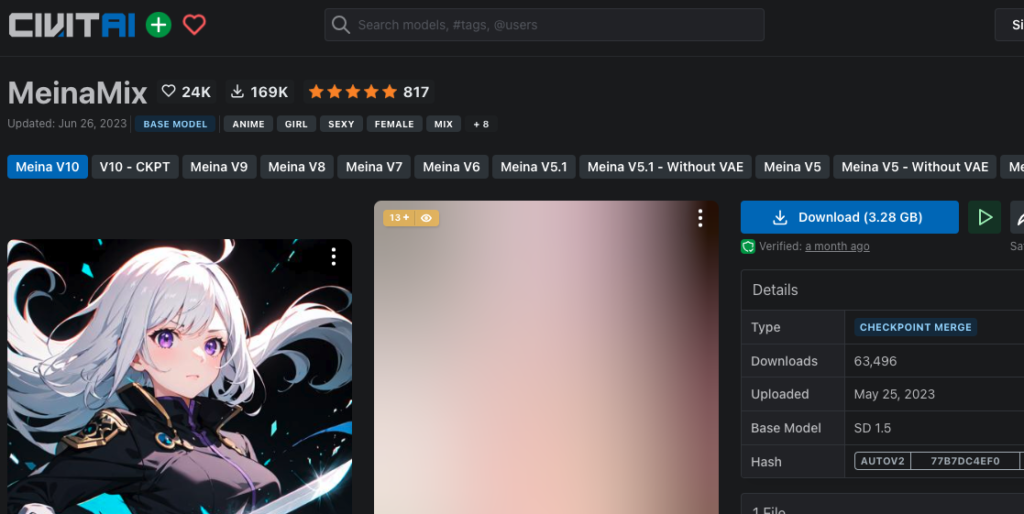
モデルをダウンロードした後、自分のGoogle Driveにアップロードします。
アップロード先のGoogle Drive上には、モデルを保存するフォルダ(例えば「sd>medels」など)を作成しておきます。
これでモデルの準備作業は完了です。
ノートブックを実行
「Copy of fast_stable_diffusion_AUTOMATIC1111.ipynb」のタブに戻り、ノートブックを実行します。
ノートブックは6つのブロックで構成されていて、それぞれのブロック左側の三角ボタンをクリックして実行していきます。
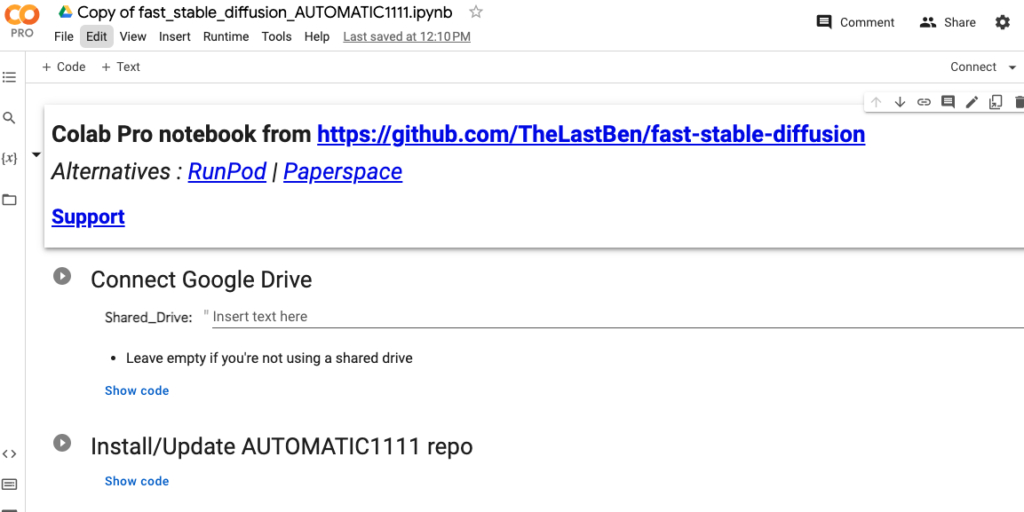
「Connect Google Drive」の実行
左側の三角ボタンをクリックします。
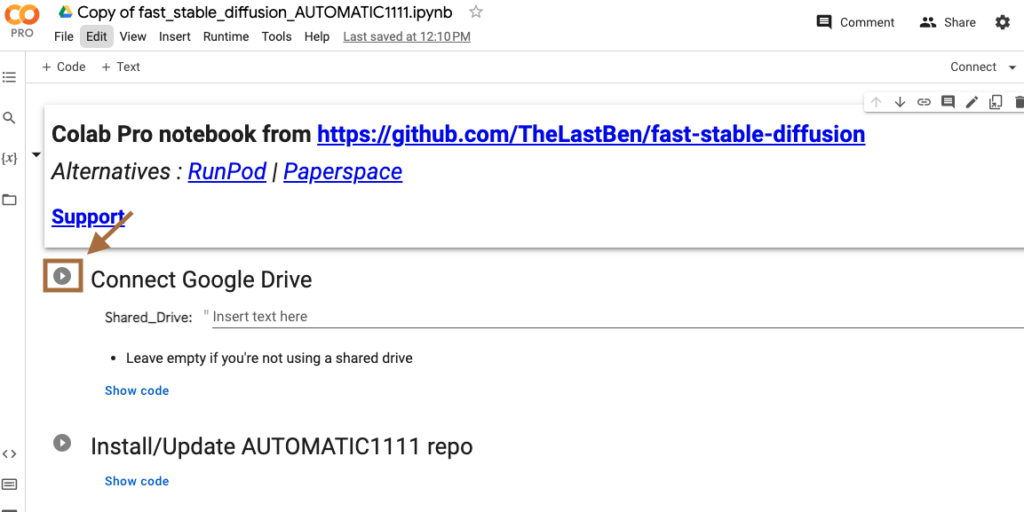
以下のような確認メッセージが出ますので「Connect to Google Drive」をクリックします。
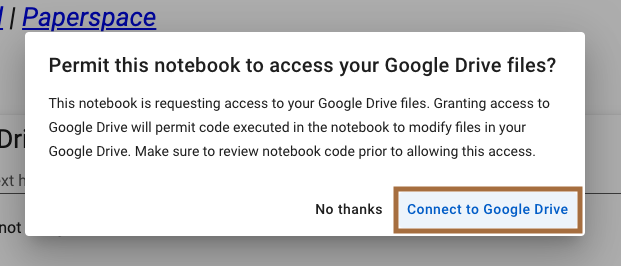
すると、認証を求められますので「許可」をクリックします。
「Done」が表示されたら完了です。
「Install/Update AUTOMATIC1111 repo」の実行

「Done」が表示されたら完了です。
「Requirements」の実行

「Done」が表示されたら完了です。
「Model Download/Load」の実行
「Path_to_MODEL」にモデルの保存先を指定します。
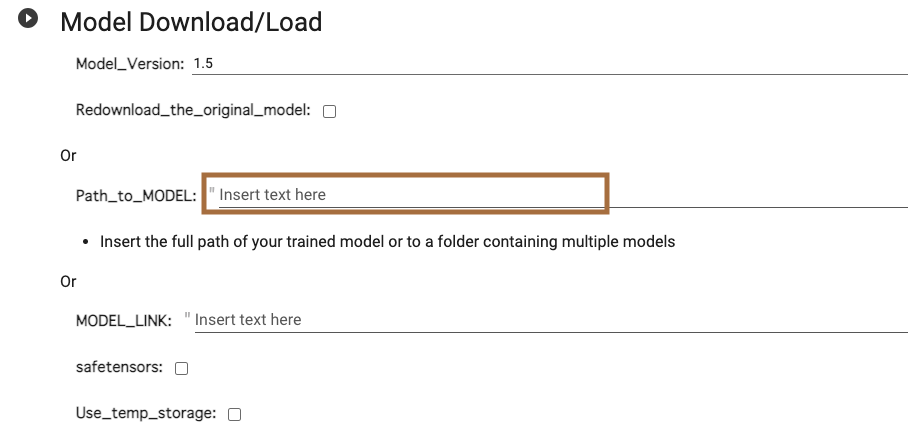
今回は「sd>models」フォルダにモデルを保存していますので、下記のようにします。
「/content/gdrive/MyDrive/sd/models/meinamix_meinaV10.safetensors」
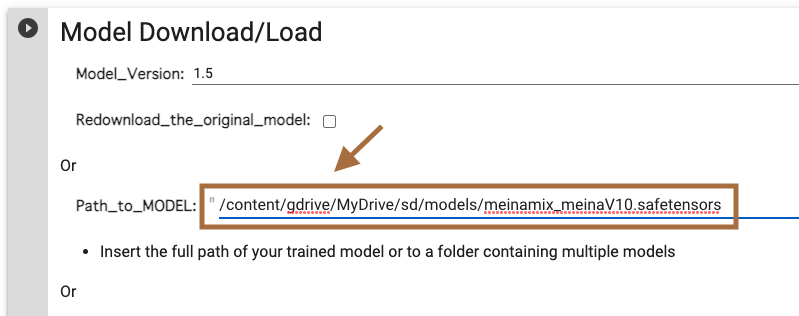
左側の三角ボタンをクリックして、「Using the trained model」表示が出れば完了です。
次の「ControlNet」は必要に応じ実行します。
「ControlNet」を使用すると、生成する人物のポーズや構図を指定することができるようになります。
今回は実行せずに次に進みます。
生成する人物のポーズや構図を設定できる機能です。
ポーズや構図はプロンプトで指定しても、思い通りの結果とはならないことが多いです。
しかし、この「ControlNet」を使うことで、ポーズや構図を指定することができるようになります。
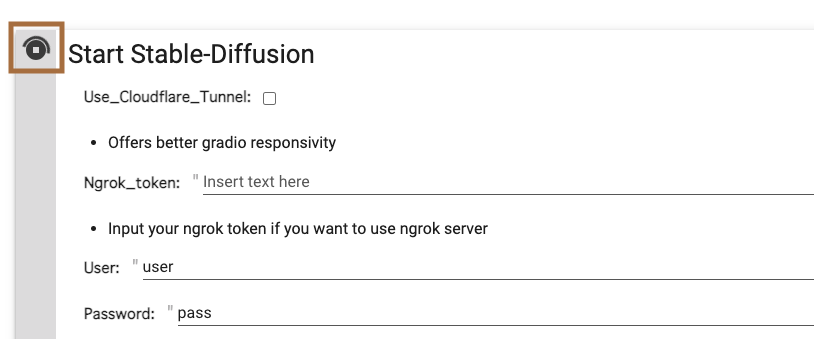
「Start Stable-Diffusion」の実行
「Connected」表示が出れば完了です。表示されたURLをクリックして、WebUIを起動します。
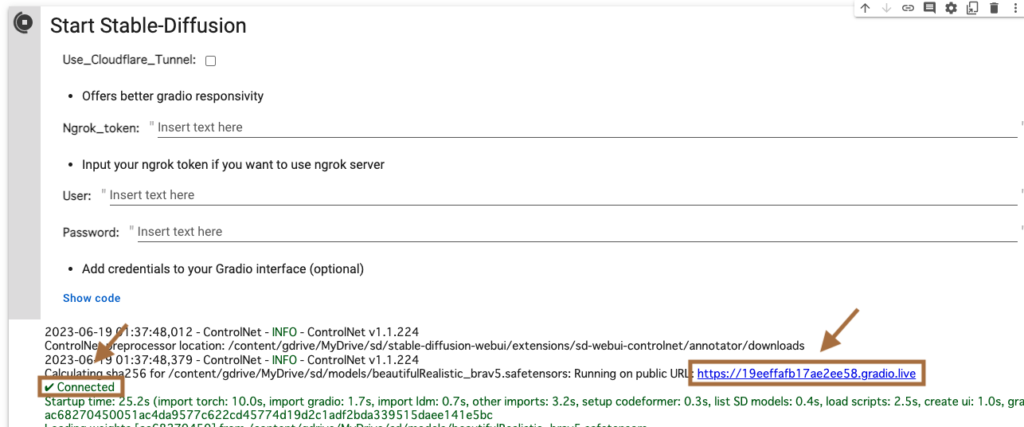
これで準備完了です。早速、プロンプトを入力して始めてみましょう!
WebUIを使う
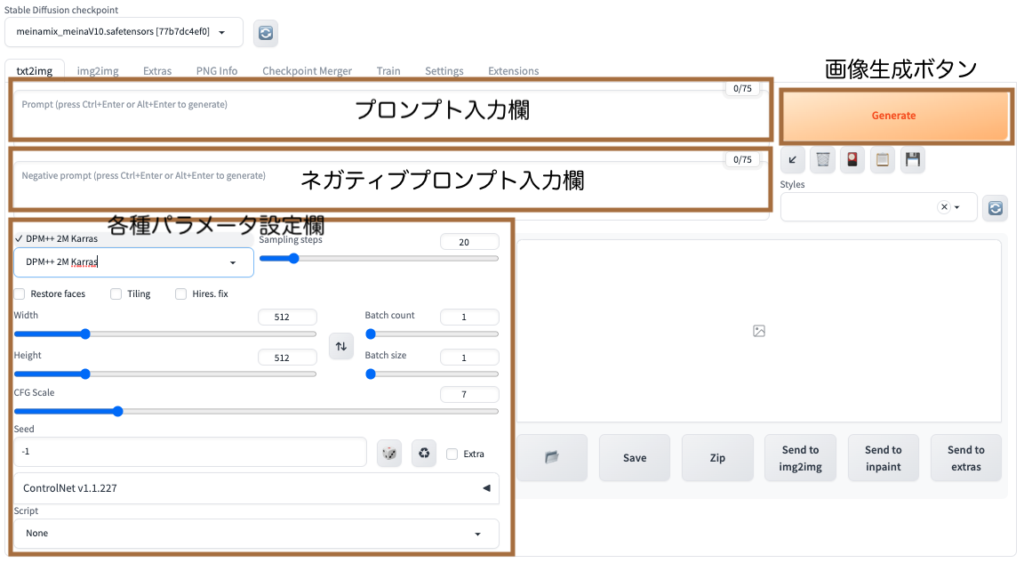
プロンプト、ネガティブプロンプト、各種パラメータを以下の通り入力して「Generate」ボタンをクリックしてみましょう。
best quality, masterpiece, detailed eyes and face, 1 girl, smiling
low quality, worst quality, normal quality, missing fingers, extra fingers
Sampling method:DPM++ 2M Karras
Sampling steps:20
Width:512
Height:512
Batch count:1
Batch size:1
CFG Scale:7
Seed:-1
Script:None

しばらくすると、このような画像が生成されます。
もし、生成された画像がぼんやりしている場合は、VAEを設定してみてください。
VAEを設定すると、画像の鮮明度を上げることができます。

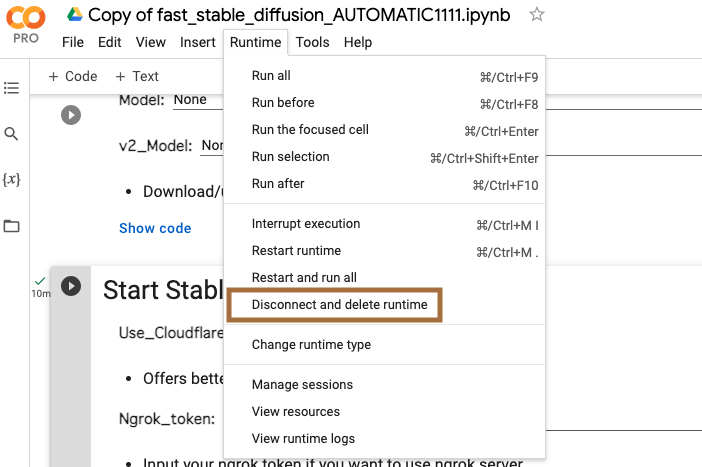
ノートブックの停止
ブラウザの「Copy of fast_stable_diffusion_AUTOMATIC1111.ipynb」タブを閉じても、「Stable Diffusion」は終了しません。
画面上で「Ctrl + s」で保存した後、四角ボタンをクリックして停止します。
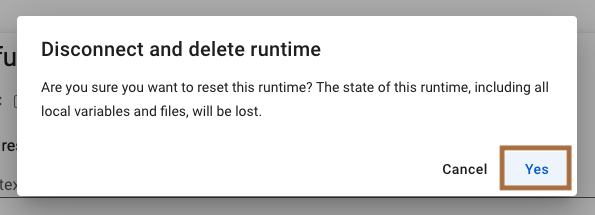
ランタイム接続の解除
「Stable Diffusion」を終了させても、ランタイムへの接続を解除しない限りGPUリソースを消費し続けます。
リソースの消費上限を超えると接続できなくなるので、ランタイムへの接続はこまめに解除しましょう。
画像生成サービスを使う
Google Colabでインストールしたりするの面倒くさい!という場合は、以下のサービスを試してみてください。
nsfw(職場閲覧注意)的なサービスですが、通常の画像も生成可能です。
Stable Diffusionで美少女画像を生成するためにはプロンプト(呪文)が重要です。プロンプトのテクニックについては以下の記事を参照してください。

プロンプト作成ツールを作ってみました
Stable Diffusionなどの画像生成AIを使って、画像を生成する時には「プロンプト」と呼ばれるテキストを入力します。
自分が作りたい画像を説明したものになるのですが、英語の単語を連ねたもので単語同士はカンマで区切るルールとなっています。以下の様なものです。
“photo realistic, Japanese girl, looking at viewer, wavy hair, tank top, close up shot”
最初の頃は全く見当がつかないので、ネットで検索してそれらしいプロンプトを見つけてコピペして使うことになります。しかし、色々なバリエーションの画像を生成したい時に、このプロンプトをいちいち修正するのが面倒です。
また、プロンプトには、どのような単語をどのような順序で並べると思った通りの画像が出てくる、というテクニックが存在します。しかしながら、色々な人が様々なプロンプトについて語っていて、正直、情報が多すぎて全体が掴めない状況になっています。
自分で画像を生成しようとなった時に、そのような不便さを感じました。
なので、簡単なチェックでルール決めされたプロンプト文が出力されるサービスを作ってみました。

是非、一度試してみてください。








コメント
コメント一覧 (3件)
[…] あわせて読みたい 【超初心者向け】Stable Diffusionの使い方を詳しく解説 – AI 課長 […]
[…] 【超初心者向け】Stable Diffusionを手軽に利用できるGoogle Colabでの使い方を解… この記事で解決できること AIでイラストや画像を作るには? […]
[…] Pixel Gnarly – AIを乗りこなして… 【超初心者向け】Stable Diffusionを手軽に利用できるGoogle Colabでの使い方を解説 – Pixel Gnarly この記事で解決できること AIでイラストや画像を […]